

Kernel vulnerabilities
With the introductory article on the kernel world, we have all the general theoretical elements that allow us to understand why it’s interesting to find flaws in the kernel.
So we’ll now look at what these flaws are. No, we’re not yet going to get our hands dirty. But this world is so vast that it’s necessary to have a global view before diving in head first. You’ll see, it remains interesting nonetheless.
By the way, if you have some knowledge of existing vulnerabilities in User-Land, you’ll see that there are many similarities.
Pointer issues
A pointer contains an address, and when we want to retrieve what’s at that address, we dereference the pointer. Unfortunately (?) there are many cases where pointers don’t point to, or no longer point to, the address the programmer intended.
For example, a static pointer is initialized to NULL in C, NULL being equal to 0x00. If no other value is assigned to the pointer and it is dereferenced, then it will create a problem because the process or the kernel will try to access the memory address 0x00 but there’s rarely anything mapped at that location. Rarely… But since this is in User-Land, we can map this memory zone and write whatever we want there.
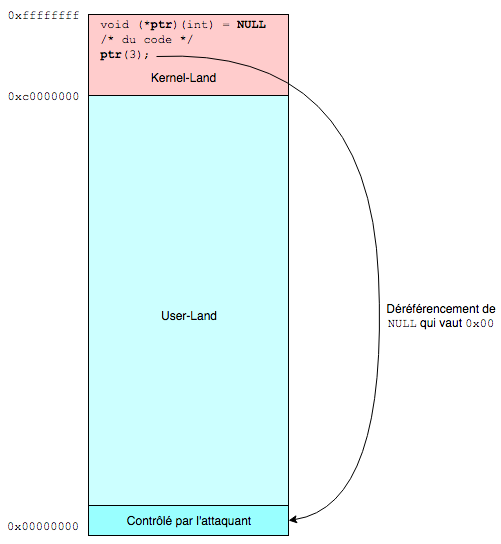
In the same way, if the value of a pointer is overwritten, for example following an overflow, then when dereferenced, at best if the memory zone is mapped, the value retrieved won’t be the one expected, and at worst there will be a panic.
So it’s very interesting for the attacker to see how to take advantage of these dereferencing issues with NULL pointers or corrupted pointers, as long as they’re not checked before being used.
Memory corruption
Memory can be corrupted at two levels. In the stack, associated with each thread when kernel code is executed (for example with syscalls), and in the heap when the kernel code needs to allocate space.
Kernel Stack
When a process is running, it has two stacks: one in user-land, and one in kernel-land.
Both work relatively similarly, however the stack in kernel-land has a few particularities: its size is limited, and all the kernel stacks of processes share the same memory range, since the kernel’s virtual memory is replicated for all processes. These stacks start and extend at different offsets within Kernel-Land.
Despite these differences, the vulnerabilities we know for the user-land stack apply very well to kernel-land (buffer overflows and variants).
Kernel Heap
The kernel needs memory to store various objects. For example, if a process opens a file, the kernel will need to record somewhere the information needed to keep track of this file opening. To do this, a kernel-internal memory allocator, optimized for it, communicates with the memory allocator at the hardware level, and requests memory pages that it splits into chunks to store the objects.
If a page is filled, a new page is requested, and the info for each page is recorded, sometimes at the beginning or at the end of the page.
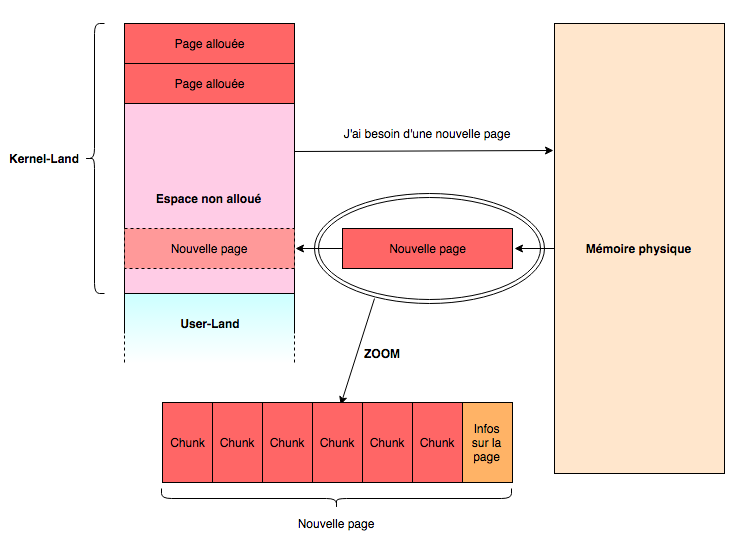
By the way, without going into the details, we can sometimes predict quite precisely the order of the chunks that will be used, so we can arrange the order of the objects we use within a page. This is an attack vector because with overflow techniques it’s possible to write over objects of our choosing, or to write over the info of the memory page being used.
Integer issues
Several issues exist with integers. The most common are integer overflows and sign conversion issues.
Integer overflows happen when we try to fit an integer that’s too large into a variable. If the integer is unsigned (so only positive values), then the behavior is often to drop the bits that “overflow”, and if the integer is signed, in most cases there’s a sign inversion.
Let’s take this example for a 32-bit architecture.
/* count is an integer */
size_t ssize;
if (count <= 0) { // [1]
return (EINVAL);
}
ssize = sizeof(myStructure_t) * count; // [2]
myList = kmalloc(ssize, __GFP_WAIT); // [3]
In this example, count will be multiplied by the size of the myStructure_t structure, which we consider to be 4 bytes. If count is greater than 0x3FFFFFFF, the check at [1] is always skipped because count is greater than zero, but following the multiplication at [2], ssize will have a value too large to fit in a size_t, which here is a value that can hold 32 bits. Indeed 0x40000000 * 4 = 0x100000000, a 35-bit value. The result is that the extra most significant bit is dropped, so the value of ssize will be 0. Thus, myList will have a smaller size than expected following [3]. All we need then is for later code to try to access or write at an expected memory location of myList to create an overflow.
We also encounter issues with integers during sign conversions. When an integer is considered signed in one place, and unsigned in another, it can then take two totally different values, which is rarely what the programmer intended, and exploitable by… us!
signed int myLen;
// [...]
/* We control myLen */
// [...]
if (myLen < 10) // [1]
memcpy(buff, ptr, myLen) // [2]
Since we control myLen we can give it a negative value that will pass the check at [1]. However, the prototype of memcpy is:
void* memcpy( void *dest, const void *src, size_t count );
so we see that count is of type size_t, which is actually an unsigned integer. Thus, our myLen will be converted to an unsigned integer that can potentially have a size much greater than 10 and thus cause an overflow at [2].
Race conditions
A race condition can happen when at least two actors are in competition, and the result of the operations differs depending on which actor acted before the other. It happens when the two actors work at the same time, when several CPUs are running for example, or when they interleave if there’s only one CPU and that CPU alternates between the two tasks to make them run with pseudo-parallelism.
So, if we slip in between kernel instructions, we can find exploitation vectors.
struct stat st;
if (stat(filename, &st) == 0)
size = st.st_size;
// [...]
buff = kmalloc(2048, __GFP_WAIT);
if (size < 2048) {
// ---------------------- [1]
while (ret > 0)
ret = vfs_read(file, buff, size, &offset);
}
In this example, a 2048-byte buff buffer is prepared to receive the content of a file. We check that the file size is less than 2048 bytes, and if it is, we copy its content into buff. But if we modify the file’s content between the check and the copy at [1], it’s then possible to create a file larger than 2048 bytes and thus cause a buffer overflow.
Other bugs
There are still plenty of other exploitable bugs. One last example: reference counters. Indeed, there are plenty of things shared between processes. The kernel will allocate memory for an object only once, and it will share this memory with the processes that need it. It keeps in memory the number of processes using it, and when this number drops to zero, the object can be freed.
But sometimes code snippets forget to notify the kernel that they no longer need the object. In this case, calling this snippet of code (which allocates without freeing) in a loop will increase the kernel’s reference counter, until an integer overflow, which can then potentially be exploited.
There we go, we’ve gone through the major bugs encountered that can lead to kernel exploitation. But then, how do we exploit them? For that, we need a few necessary reminders about computer architecture.