

Architecture reminders
Before going further, we need to briefly talk about computer architecture. Indeed, in user-land, there’s an abstraction layer that lets us not worry too much about the architecture (although it’s still necessary to know calling conventions, the number of bits handled, etc.), whereas the kernel is this layer, so thinking we can write correct exploits without knowing the rudiments of computer architecture is clearly not imaginable.
This article isn’t meant to be exhaustive on this topic either, so we’ll only talk about the key elements that interest us, directly or indirectly, for the exploitation of vulnerabilities within the kernel.
Processor
A CPU has its own instruction set, allowing it to perform operations, modifications to the execution flow, or to modify memory. Since memory accesses are relatively slow, a CPU has registers. We already talked about registers in the article on memory management. These are small memory areas within a CPU that are accessible instantly and are used to store values for calculations, to keep information about current structures, etc.
As for instruction sets, there are two main families: RISC (Reduced Instruction Set Computer) and CISC (Complex Instruction Set Computer). RISC instructions have a fixed size and are executed in one clock cycle, while CISC instructions have variable sizes and are executed in one or more clock cycles.
Furthermore, computers can have one or several CPUs (UniProcessor UP or Symmetric MultiProcessing SMP).
Interrupts
When a series of instructions is being executed, it’s possible that an event occurs and interrupts the execution flow. The origin can be either software or hardware.
- In the case of software interrupts, we say they are synchronous since the same code replayed will trigger the same interrupts.
- In the case of hardware interrupts, we say they are asynchronous since they can happen at any time (a disk that has finished its work, a network card that has finished receiving a packet, etc.).
Each type of interrupt has a unique number associated with a routine to be executed. The CPU has a special register that tells us which routine corresponds to which interrupt number. This register points to the Interrupt Vector Table. As you can imagine, it would be interesting to modify this table…
Since CPUs have two execution modes, privileged and non-privileged, as we mentioned in the introductory article on the kernel world, it’s possible, using instructions provided by the CPU in non-privileged mode, to make interrupts to execute privileged code, for example so that the kernel executes the faulty code, and thus exploit the vulnerability.
Memory management
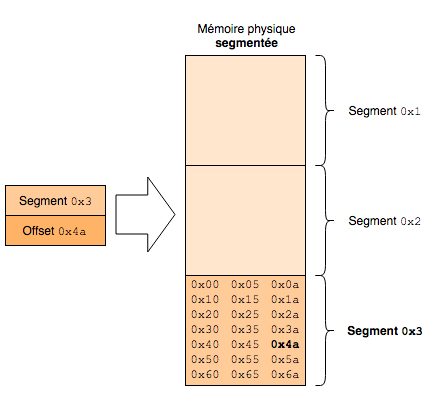
Access to physical memory can be done in a segmented way for some CPUs, or linearly (the majority nowadays).
In segmented addressing, you have to give the segment number and then the offset of the data within that segment to retrieve it, whereas with linear addressing, we can have a 1:1 mapping of addresses, but we can also have paging to have virtual memory zones. In the case of paging, it’s the MMU (Memory Management Unit) that takes care of translating a virtual address into a physical address, going through the page tables.
Here’s a diagram of a segmented physical memory:
Then a diagram of the two types of linear memory, one with the 1:1 mapping and the other using the paging system and virtual memory:
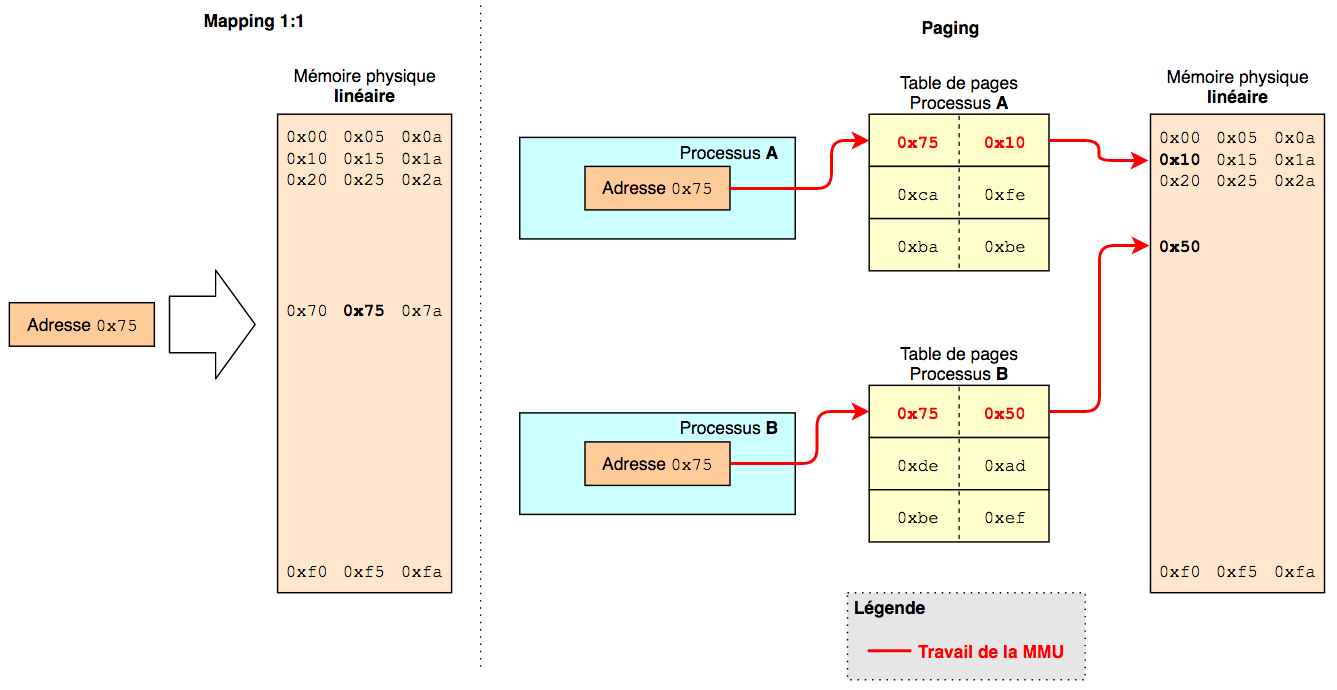
However, since the virtual address -> physical address translation operation is somewhat costly, there’s a cache called the Translation Lookaside Buffer (TLB) that keeps in memory the correspondence between virtual addresses and physical addresses. This is handy, for example, when iterating over an array so that we don’t have to find the address of the start of the array in physical memory at each iteration.
Of course, since each process has its own memory range and its own page table, the TLB has to be flushed at each change of the currently running process.
However, in the case where memory is shared (one part for the kernel, one part for the process), even if there’s a process change, it’s not necessary to flush the kernel’s TLB since the kernel’s page table is replicated for each process, and remains unchanged. Its TLB therefore remains the same.
32-bit & 64-bit
We’ll finish with a little aside about a few particularities of x86-64 CPUs.
- All 32-bit registers (EAX, EBX, …) are extended to 64 bits (RAX, RBX, …)
- 8 new registers (R8-R15) are created
- An NX (Non-eXecutable) bit is present by default for allocated pages to decide whether or not they are executable memory zones
- The function calling convention has been modified: arguments are no longer passed via the stack by default, but via registers.
Apart from these four major differences (there are many others), most of the things we know in x86 architectures remain valid.
In the next article, we’ll see the methodology for developing an exploit in a clean and methodical way.
[ Next article in progress ]